

Last week, I discussed John Anderson’s ACT-R theory of cognitive skill acquisition. ACT-R is an ambitious theory tackling a big question: how do we learn things? Anderson’s theory makes compelling predictions and has quite a bit of evidence to back it up.
Yet understanding the mind is like the story of the blind men and the elephant. One touches the tusk and says that elephants are hard and smooth. Another touches the leg and says they’re rough and thick. A third touches the tail and says they’re thin and hairy. What theory you arrive at depends on what you choose to grasp.
ACT-R was developed using a paradigm of problem-solving, particularly in well-defined domains like algebra or programming. This relatively simple paradigm is then assumed to represent all of the broader, messier kinds of intellectual skills that people apply to real-life situations.
But what if we take a different paradigm as our starting point?
In this essay, I take a deeper look at Walter Kintsch’s Construction-Integration (CI) theory. This theory uses the process of understanding text as its starting point for a broader view of cognition. As I’ll show, it both complements and contrasts the ACT-R model we discussed previously.1

How Do We Comprehend What We Read?
What is going on right now, in your head, so that you can understand the words I’ve typed?
At a basic level, we understand that the brain has to convert these black squiggles into letters and words. But what happens next? How do we actually make sense of it? We are pretty good at getting machines to recognize text from a photo. But we’re a lot worse at getting these machines to understand what they read in ways that closely resemble human beings.
Part of the reason this is so hard is that language is ambiguous. Take the phrase, “time flies like an arrow.” What does it mean? For most of us, the expression is a metaphor—it evokes an idea of time passing forward in a straight line. Except, taken literally, there are several possible situations this sentence could refer to.
The joke in linguistics is “time flies like an arrow, fruit flies like a banana.”
How, then, do we know when reading that there isn’t a species of fly called the “time fly,” and they happen to be particularly fond of a kind of projectile?

The vague, but correct, answer is that we use our world knowledge to constrain which interpretation is the most reasonable. We merge the literal words of the text with what we already know to effortlessly form a picture of what the sentence means. Walter Kintsch’s Construction-Integration theory is a hypothesis about how we do this.
Fundamental Concept: Propositions
The basic building blocks of Kintsch’s theory are propositions. A proposition is a way of rewriting an English sentence that makes clear a single, literal meaning. Propositions are useful because English sentences can be ambiguous, or they may be arbitrarily complicated (and thus contain many propositions).
A sentence like “they are flying planes” could be interpreted as two propositional structures: FLY[THEY, PLANES] or ISA[THEY, FLYING[PLANE]]. The first roughly translates to the idea that there are some people (they) who are piloting (flying) planes. The second is a statement that there are some things (they) which happen to be planes for flying.
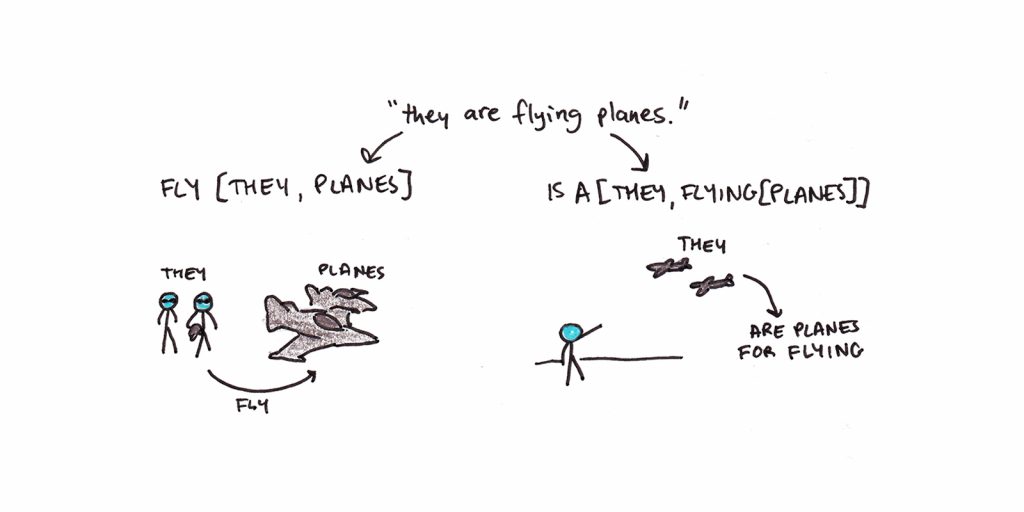
Think of a proposition as a fundamental building block of meaning. We can even form complex meaning by connecting together a network of these atomic propositions.
Propositions are a useful tool, but do they have any psychological reality? Kintsch argues that they do:
- Propositions tend to be recalled entirely or not at all.
- People tend to recall things based on their proximity in the propositional structure rather than the actual text. For example, given the sentence “The mausoleum that enshrined the tzar overlooked the square,” subjects who are given the cue “overlooked” are more able to recall “square” than “tzar.” This happens even though “tzar” and “overlooked” are closer together in the actual text.
- Recall of a text depends on the number of propositions, not the number of words. This is another clue that we use something like propositions to think at the level of meaning.
Is all knowledge propositional? Probably not. We have mental imagery, bodily sensations, and far more than we can express in words. Experiments on mental rotation showed conclusively that the idea of a “mind’s eye” is not just a convenient metaphor. What things look like when we imagine them does impact our reasoning.
However, Kintsch argues persuasively that we can treat knowledge as propositional. The benefit of this approximation is that it allows us to represent diverse types of knowledge in the same way, to make it easier to model.
Step One: Convert Text to Propositions
The first step in Construction-Integration is to construct a more-or-less literal representation of the text. This involves transforming patterns of dark and light hitting our eyeballs into letters and words. We then need to convert those words into propositions that represent what the text is saying. Kintsch’s model omits the details of this visual transformation and parsing function. However we manage to do it, the theory assumes we read text and develop a few propositions in our working memory, each literally derived from the text.
At this stage, we are not yet using context to disambiguate meanings. So the phrase “they are flying planes” would activate both FLY[THEY, PLANES] and ISA[THEY, FLYING[PLANE]]. Both meanings are activated, but the degree of activation may depend on its overall likelihood, independent of the current situation.
This is the “construction” phase of the Construction-Integration model. Text is converted into the propositions it literally implies. If the sentence is ambiguous, this will include multiple, contradictory meanings.
Step Two: Build Propositions into a Textbase
These atomic, literal propositions now must be linked together. This network of propositions is called the textbase.
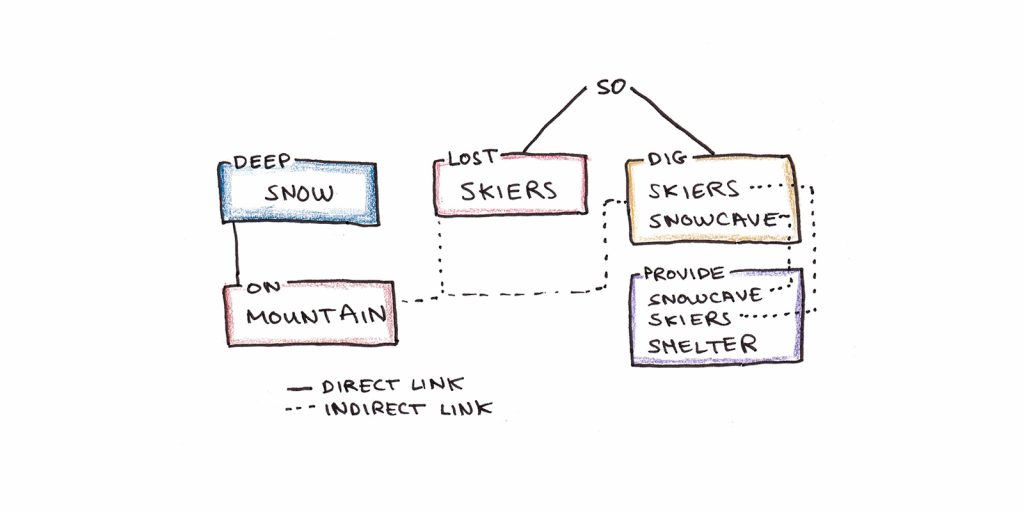
Kintsch provides the following text, and its associated network of a textbase, as an example:
“The snow was deep on the mountain. The skiers were lost, so they dug a snow cave, which provided them shelter.”
Becomes the following textbase:
Step Three: Link Textbase to Prior Knowledge
A proposition on its own doesn’t mean very much. The sentences “the snow is deep” and “the glarb is snarf” are both interpretable as DEEP[SNOW] and SNARF[GLARB]. The difference is that “snarf” and “glarb” don’t activate anything in prior knowledge, so they’re essentially meaningless.
It is the link to prior understanding that gives words their meaning. This understanding itself is also assumed to be a network of propositions. Instead of just the momentary network created by reading the text, this deeper understanding is thought to be a vast, dormant network of connections in long-term memory.
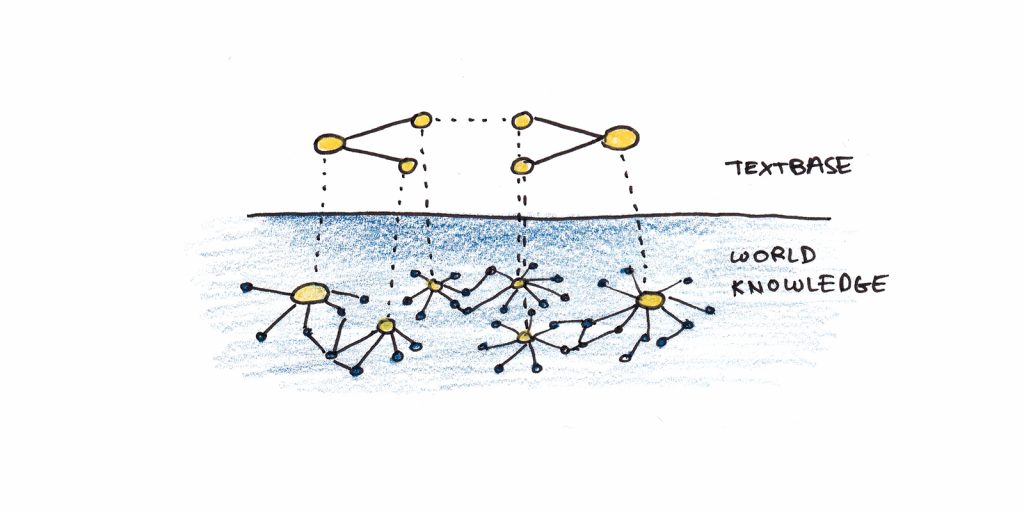
As we read, we activate prior knowledge. The likelihood of retrieving this prior knowledge depends on the retrieval strength for the concept, given the cue word. This may be near 100% for familiar words, but obviously, it will be lower if the word is new or unfamiliar.
Thus, creating a textbase is not just creating a new network. We must then overlay this textbase network on top of a mostly dormant network created from past experience.
Step Four: Stabilize the Network of Propositions
Finally, the network of propositions will stabilize. This is the “integration” phase of Construction-Integration theory. This happens because some of the possible meanings will not match with other information in the text, and also because prior world knowledge constrains which meanings are activated in the network.
We can see how this might happen with the ambiguous phrase, “they are flying planes”:
- Initially, both senses are active, although one may be more active than the other depending on its prior likelihood. (For me, the sense that “they” referred to pilots and not planes came first.)
- Another sentence follows, “They recently graduated from flight school.”
- This new information activates other nodes which are connected through our prior knowledge. We know planes can’t graduate from flight school, which suppresses the inappropriate meaning.
- In contrast, you might have the unexpected sentence, “They are really noisy when they pass by overhead.” The idea of pilots being noisy seems less plausible, so the alternative meaning that those objects were flying planes becomes more likely.
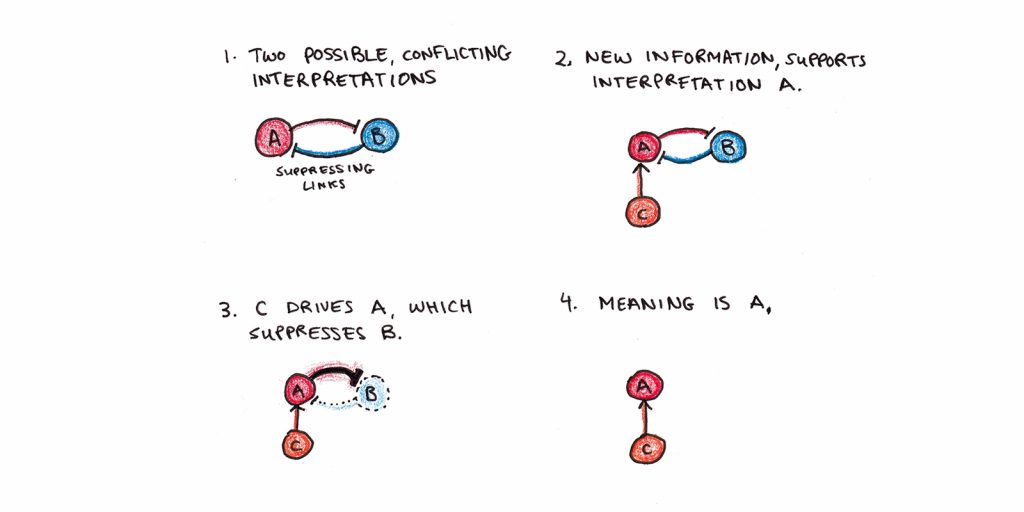
Stabilization happens between nodes simultaneously as they activate or weaken their connected neighbors. The “channels” through which this activation/suppression flows are a combination of the textbase given by the environment and our prior world knowledge. If the text makes the meaning explicit, a good reader will rely on the textbase over their prior world knowledge. However, if the text does not provide many inferential steps, we will fill in the meaning using our prior world knowledge.
Putting the Steps Together
Let’s recap the basics of how Construction-Integration says we make sense of text:
- We convert English sentences into propositions. These are the atomic, unambiguous meanings in the text.
- As we read, we link the propositions together to form a textbase. This network of propositions forms the literal interpretation(s) of the text.
- The nodes of the textbase activate corresponding nodes in our prior world knowledge. Thus we have two networks—a momentarily activated one consisting of the text’s literal meaning(s), and a vast, mostly dormant network of prior knowledge.
- Nodes activate related meanings and suppress contradictory ones. The textbase drives this activation, but it flows through our existing world knowledge. This allows us to make obvious inferences that aren’t literally in the text. It’s also how we suppress inappropriate meanings given the context.
- This jostling of activation and suppression eventually stabilizes into a coherent structure. That structure is the meaning of the text.
Although I’ve presented this as a series of steps, these processes are likely acting in parallel. Each word you read simultaneously updates the textbase, activates prior knowledge, and stabilizes the structure.
Getting the Gist
We often remember the gist of what we read, even as the literal contents rapidly fade from memory. Consider the following text:
“Jane drove to Alfalfa’s, picked up some fresh fruit, a halibut steak, and some Italian cheese for dessert, and paid with her credit card.”
Although it’s nowhere in the text, the proposition “Jane bought groceries” would be highly active for this sentence. Because of our world knowledge, when we read a series of propositions we associate with grocery shopping, the central theme of the sentence becomes more and more active. The overall meaning may be more retrievable from our long-term memory than any of the details because of this flow of activation.
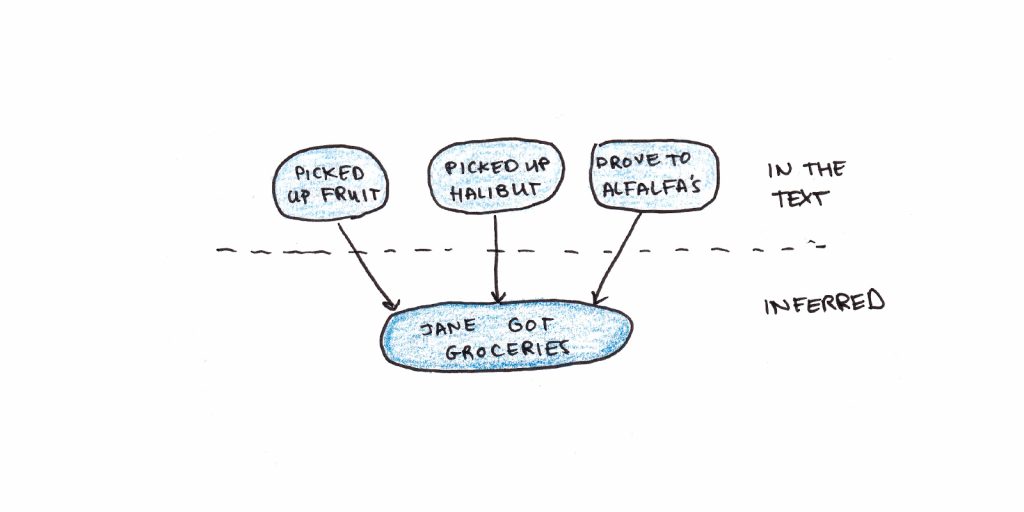
This pattern also helps explain why we generally seem to recall meaningful patterns better than arbitrary details and why prior knowledge is crucial for learning.
Implications of the CI Model for Cognition
The idea of a vast network of simultaneously firing nodes that suppress and activate each other may seem difficult to imagine, let alone draw any conclusions from. But I’ll do my best to share what the CI model implies.
1. Meaning is Shallow
One implication of the CI model for comprehension is that meaning is relatively shallow. When you read a word, its meaning is defined by the network of related activation. What words mean in a situation will often be quite limited compared to all their potential meanings.
Research on transfer-appropriate processing bears this out. Researchers gave participants stories about a piano that were the context of either moving furniture or playing music. The result was that whether “heavy” or “loud” was a better retrieval cue depended on which story they heard.
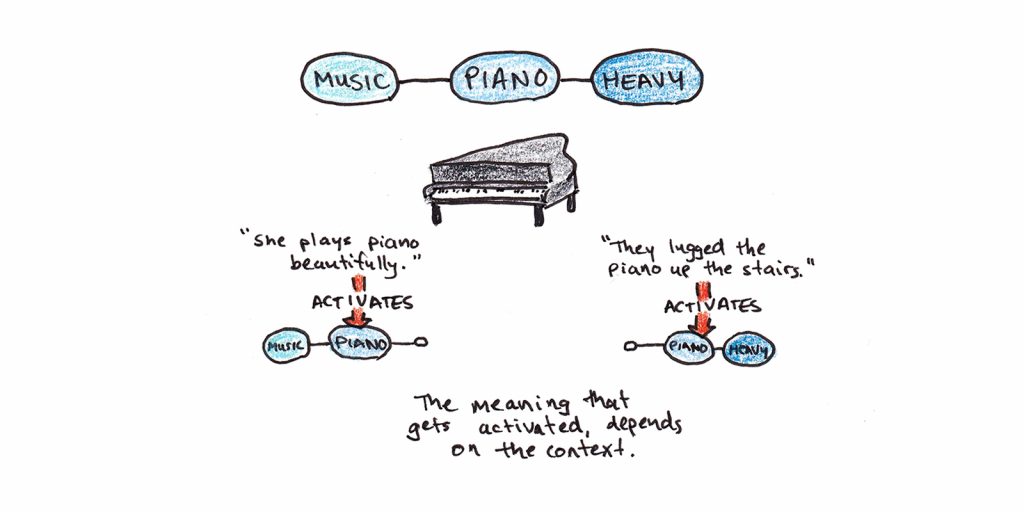
This is related to Nick Chater’s argument in The Mind is Flat. Our conscious awareness is a few spots of light on a broader tapestry. Our moment-to-moment experience is surprisingly impoverished, but we have an illusion of depth because we can access our existing knowledge as soon as we want to think about it.
The meaning of a word, sentence or even an entire book isn’t inherent to the text. It’s a collaboration between literal words and an active reader.
2. Working Memory Isn’t Limited for Familiar Tasks
In addition to his CI model, Kintsch worked with Anders Ericsson to explain how experts are seemingly not hampered by working memory limitations. They propose that experts develop long-term working memory.
To briefly recap, working memory is what you can keep in mind simultaneously. It is famously limited, perhaps to as little as four chunks of information. Yet experts seem to be free of this limitation in performing tasks.
This is particularly relevant to a theory of text comprehension because, for familiar texts, we are all experts. In one experiment, subjects read a passage about the invention of the steam engine, presented one sentence at a time. Except in-between they were presented distractor sentences not about the story. The result was that comprehension was barely affected.
This may not seem too surprising—after all, we regularly read stories while having our attention flit back and forth. However, if you tried the same thing with phone numbers or nonsense syllables the distraction would most likely erase whatever you were previously paying attention to.
Ericsson and Kintch’s answer is that we overcome working memory limitations by creating retrieval structures. This means that, through practice, we can remove the constraint of our working memory—effectively becoming smarter. However there’s a big catch: these retrieval structures only help for the material we’ve practiced. Thus you can get smarter, but don’t expect it to transfer to unfamiliar tasks.
3. Problem-Solving or Problem Understanding?
Last week, I suggested that ACT-R and CI offer different accounts for how we think. How do the two compare?
In many ways, the two theories sit together nicely. ACT-R is simply a more elaborate description of the procedural memory system, whereas CI offers a more detailed account of declarative memory.
Yet there are contrasts. ACT-R sees thinking as problem-solving, but CI sees thinking as comprehension. ACT-R bases the learning of skills on acquiring and strengthening IF-THEN production rules. CI bases learning on a process of spreading activation that allows us to understand a situation effortlessly.
These different frameworks suggest different pictures of transfer. ACT-R is more pessimistic. Skills transfer to the extent they share productions, and most productions are highly specific. In contrast, CI argues that world knowledge forms a background for interpreting tasks. Every little bit of knowledge adds to that background, even if none of it is decisive.
Despite these contrasts, I shouldn’t exaggerate the differences. Both models paint a picture in which learning is domain-specific, and extensive experience is required for expertise. Both models are firmly within cognitive science, assume a limited working memory capacity and an information-processing model for thinking.
Both may be true, but they emphasize different parts of the mind. Like the blind men and the elephant, we shouldn’t be misled to think either paints a complete picture.
Final Thoughts on Construction-Integration
I’ve barely scratched the surface of implications from Kintsch’s CI theory. In later chapters, he explores how we solve word problems in mathematics, the source of cognitive biases that lead to irrational decisions, and even how such a model might support a sense of self. I highly recommend his book, Comprehension: A Paradigm for Cognition, for those who want to learn more.
 I'm a Wall Street Journal bestselling author, podcast host, computer programmer and an avid reader. Since 2006, I've published weekly essays on this website to help people like you learn and think better. My work has been featured in The New York Times, BBC, TEDx, Pocket, Business Insider and more. I don't promise I have all the answers, just a place to start.
I'm a Wall Street Journal bestselling author, podcast host, computer programmer and an avid reader. Since 2006, I've published weekly essays on this website to help people like you learn and think better. My work has been featured in The New York Times, BBC, TEDx, Pocket, Business Insider and more. I don't promise I have all the answers, just a place to start.