

Recently, I wrote a defense of psychologist John Carroll’s claim that what separated stronger and weaker students wasn’t a fundamental difference in learning potential, but a difference in learning rate. Some people learn faster and others more slowly, but provided the right environment, essentially anyone can learn anything.
In arguing that, I primarily wanted to dispute the common belief that talent sets hard limits on the skill and knowledge you can eventually develop. Not everyone could become a doctor, physicist or artist, the reasoning goes, because some people will hit a limit on how much they can learn.
However, in arguing that the primary difference between students was learning rate, I may have also been committing an error!
A recent paper I encountered suggests that the rate of learning among students doesn’t actually differ all that much. Instead, what differs mostly between students is their prior knowledge.1
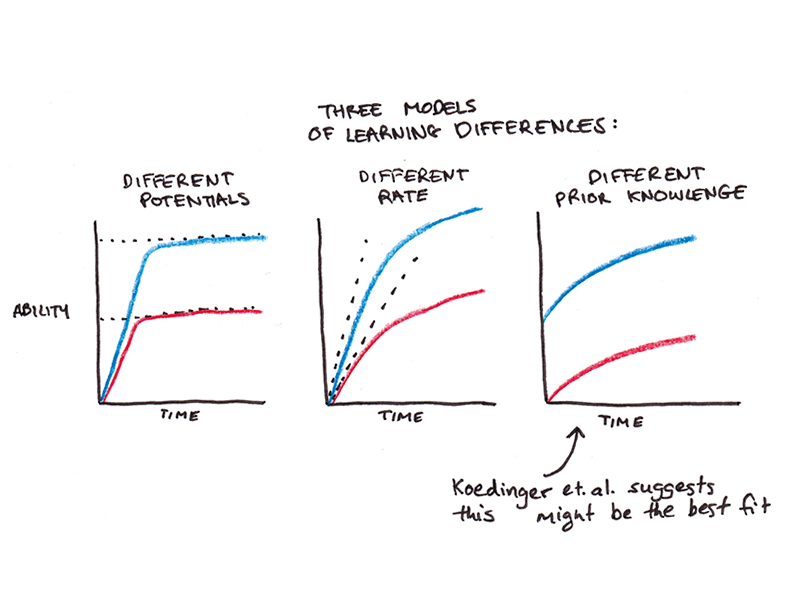
“An Astonishing Regularity”
The paper, “An astonishing regularity in student learning rate,” was authored by Kenneth Koedinger and colleagues. They observed over 6000 students engaged in online courses in math, science, and language learning, ranging from elementary school to college.
By delivering the material through online courses, the authors could carefully track which lessons, quizzes and tests the students took.
The authors then broke down what students were learning into knowledge components, and created a model that defined the individual factors responsible for learning each topic.
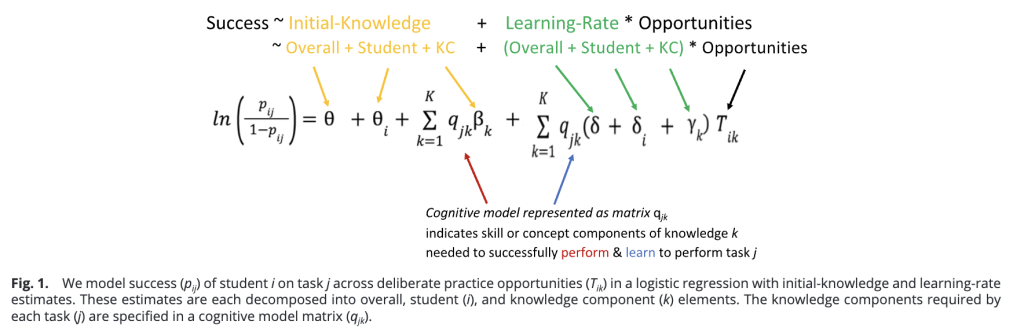
The model breaks what students learn into prior knowledge inferred from their performance on test items before instruction begins, and a measure of new learning. The actual details of the model are a little technical, so if you’re interested, you can read the paper or see this footnote.2
Immediately, the authors observed that students enter classes with substantial differences in prior knowledge. The average pre-instruction performance was 65%, with more poorly performing students at 55% and better performing students at 75%.
This difference in prior knowledge translated to differing volumes of practice needed to achieve mastery, which the authors defined as an 80% probability of success. Strong students needed roughly 4 opportunities to master a given knowledge component, whereas weaker students required more than 13. A dramatic difference!
However, the rate of learning between strong and weaker students was surprisingly uniform. Both groups improved at the same rate—achieving roughly a 2.5% increase in accuracy per learning opportunity. It was simply that the better students started with more knowledge, so they didn’t have as far to go to reach mastery.
While the authors did find a slight divergence in learning rates, it was dwarfed by the impact of prior knowledge. According to this model, students required an average of seven practice exposures per knowledge element to achieve mastery. When the level of prior knowledge was equalized between “fast” and “slow” learners, the “slow” learners only needed one additional practice opportunity to equal the rate of the “fast” learners.
If All Learners are Equally Fast, Why Do Some Have So Much More Knowledge?
This result surprised me, but it wasn’t the first time I have encountered this claim. Graham Nuthall made a similar observation in his extensive research in New Zealand classrooms, finding that students required roughly five opportunities to learn a given piece of knowledge, and the rate did not vary between students—although prior knowledge did.
Still, it raises an obvious question: if learning rates are equal, why do some students enter classes with so much more prior knowledge? Some possibilities:
- Some students have backgrounds outside of school that expose them to greater knowledge. One of the famous results of early vocabulary learning is that children from affluent backgrounds are exposed to far more words than those from poor and working-class socioeconomic backgrounds.
- Some students might be more diligent, curious and attentive. The authors note that their learning model fits the data much better when you count learning opportunities, not calendar time elapsed. Thus, if a student gets far more learning opportunities within the same class (by paying attention to lectures, doing the homework, etc.) than a classmate, they will have dramatically different overall learning rates, even if their learning rate per opportunity is the same.
- Perhaps learning rate is uniform only in high-quality learning environments. A common finding throughout educational research is that lower aptitude students benefit from more guidance, explicit instruction and increased support. It might be the case that learning rates diverge for less learner-friendly environments than the one studied here.
Another possibility is that small differences in learning rates tend to compound over time. Those who learn faster (or were given more favorable early learning environments) might seek out more learning and practice opportunities, resulting in bigger and bigger differences accumulated over time.
In reading research, Keith Stanovich was one of the first to propose this Matthew effect for reading ability. Those with a little bit of extra ability in reading find it easier and more enjoyable to read, get more practice, and further entrench their ability.
Still, a countervailing piece of evidence to this view is the fact that the heritability of academic ability tends to increase as we get older. Teenagers’ genes are more predictive of their intelligence than younger children’s genes are. That kind of pattern doesn’t make sense if we believe large gaps in academic ability are simply due to positive feedback loops—that would suggest those who, through random factors, were above their predicted potential would continue to entrench their advantage, rather than regress to the mean.
Those remaining questions aside, I found Koedinger’s paper fascinating, both for providing a provocative hypothesis regarding learning, and their effort to systematically model the knowledge components involved in learning, offering a finer-grained analysis than many experiments that rely only on a few tests.
Footnotes
- Thanks to Barbara Oakley for bringing the paper to my attention!
- The authors model performance of student i on task j. Key to the equation is the matrix q, which models the performance on test items by basic knowledge components. The building blocks of knowledge must be inferred based on test performance, rather than observed directly, so each possible q represents a hypothesis about which knowledge components are involved in a given instructional and assessment episode. Given student data, q is calculated to best fit the actual student performance data.
 I'm a Wall Street Journal bestselling author, podcast host, computer programmer and an avid reader. Since 2006, I've published weekly essays on this website to help people like you learn and think better. My work has been featured in The New York Times, BBC, TEDx, Pocket, Business Insider and more. I don't promise I have all the answers, just a place to start.
I'm a Wall Street Journal bestselling author, podcast host, computer programmer and an avid reader. Since 2006, I've published weekly essays on this website to help people like you learn and think better. My work has been featured in The New York Times, BBC, TEDx, Pocket, Business Insider and more. I don't promise I have all the answers, just a place to start.